Results
While every organization is different, disciplined modernization programs consistently deliver predictable outcomes: lower run-rate cost, clearer operational visibility, fewer preventable incidents, and teams that can move faster with confidence.
Project summary
| Customer | Problem | Solution | Financial result | People result |
|---|---|---|---|---|
| F100 Manufacturer | SolarWinds noise; missed outages; weak visibility for unique and complex services | Multi‑data center clustered Prometheus architecture with self‑service automation | $1M less over 3 years vs licensing and remediation costs | Maintained ops headcount while scaling infrastructure 4x; team sees issues before customers call |
| Commercial / Enterprise IT | VMware licensing increases under Broadcom; migration risk and skills gap concerns | Proxmox migration pattern, enablement, and backstop with periodic health checks | $100K per year reduction in licensing spend (initial small project) | Team gains confidence and operational muscle without adding fragility |
| Startup | Need to ship a customer-facing web application quickly with limited engineering capacity | AI-augmented build approach with tight scope control and support model | Built in 3 weeks with 2 people (vs ~3 months with 3 people without AI leverage) | Small team delivers faster, learns the patterns, and sustains the system post-launch |
PaaS APM (Internal and External Facing)
Multi-data center Prometheus architecture for a complex IaaS and platform environment.

Problem
- SolarWinds produced high volumes of noise with low signal.
- Customer-impacting outages were missed or detected too late.
- Limited visibility for unique services and complex dependencies.
- Inconsistent alarm design and poor operational runbooks.
- Trend and capacity data were not retained long enough to support planning.
Solution
- Technology: Clustered Prometheus across data centers.
- Automation: End-user onboarding and instrumentation.
- Execution: Phased rollout to reduce risk.
- Interfaces: Standards, escalation paths, runbooks.
- Scale: Startup → Fortune 100 IaaS.
Results
- Financial: ~$1M savings over 3 years.
- People: 4× infrastructure growth with same ops team.
- Operational: Issues detected before customers call.
Proxmox Virtualization
A migration and operating pattern to reduce virtualization run-rate cost without creating new operational risk.

Problem
- Broadcom-driven VMware licensing increases and uncertainty.
- Teams interested in alternatives but not comfortable without a backstop.
- Migration risk: operational confidence, training, and day-2 operations.
- Fear that cost savings could become a reliability or security liability.
Solution
- Technology: Proxmox VE-based virtualization with a practical HA, backup, and recovery pattern.
- Enablement: Deploy alongside your team, document operating standards, and train for day-2 operations.
- Backstop: Provide periodic health checks and escalation support so the platform remains an asset, not a risk.
- Execution: Start with a bounded pilot to de-risk the approach before scaling.
Results
- Financial: Initial project reduced Broadcom-related licensing spend by ~$100K per year.
- People: Teams gain confidence through a repeatable pattern and an experienced backstop.
- Operational: Easily scaled and supported with enterprise class support available.
Startup Web App Build and Support
AI-augmented delivery that compresses time-to-value without sacrificing maintainability.
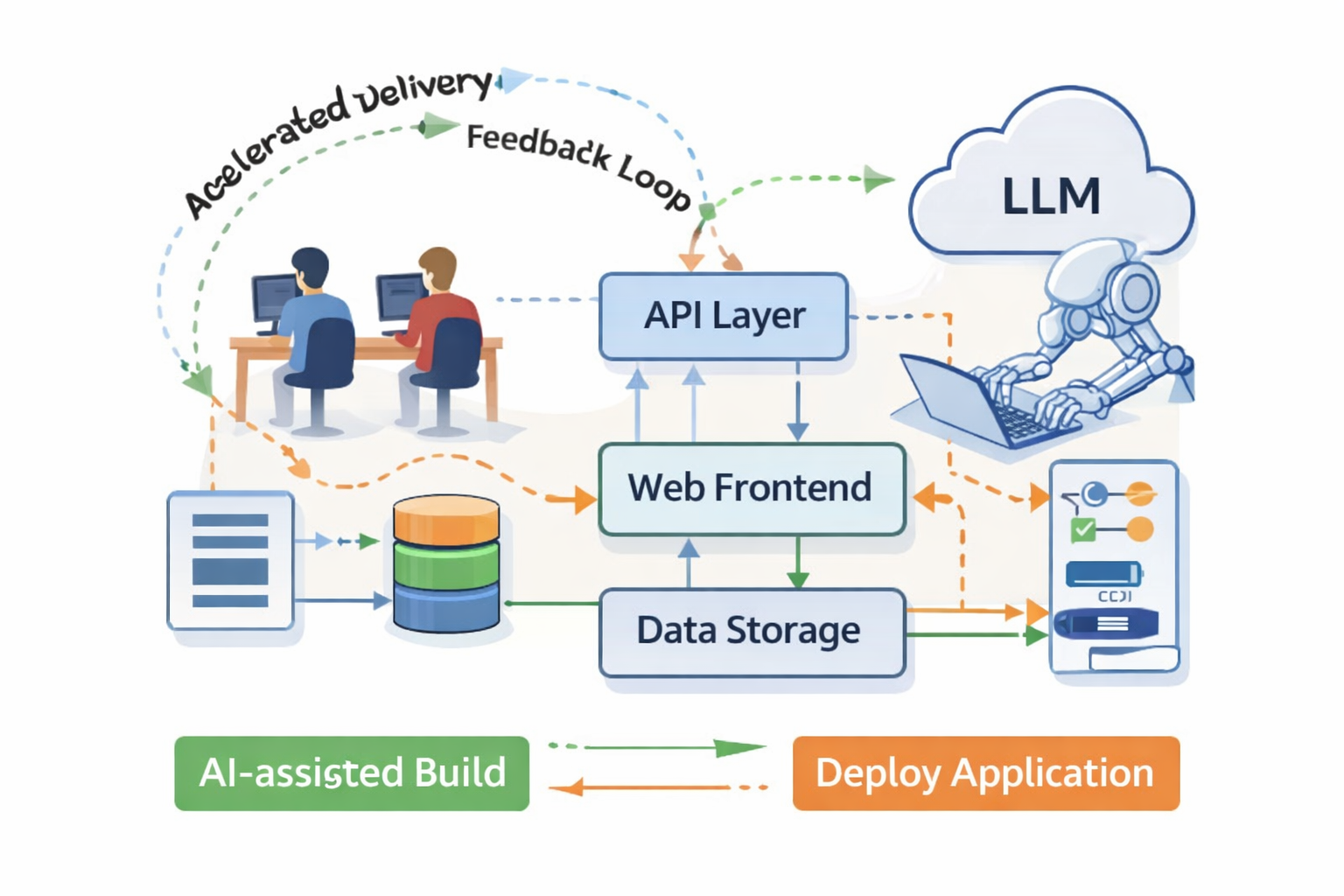
Problem
- Need to launch a customer-facing web app on an aggressive timeline.
- Limited engineering bandwidth and a high opportunity cost of delays.
- Risk of accumulating architecture debt while moving quickly.
- Support expectations immediately after launch.
Solution
- Approach: AI used as a build partner with disciplined scoping, review gates, and coding standards.
- Resources: Two-person delivery team with clear ownership and rapid iteration loops.
- Execution: Three-week build with integrated support and operational readiness.
- Interfaces: API-first design and instrumentation baked in from day one to support stability and growth.
Results
- Financial: Delivered in 3 weeks with 2 people (versus an estimated 3 months with 3 people without AI leverage).
- People: The team internalized a repeatable delivery pattern and could sustain the system post-launch.
- Operational: Ongoing operations were easily picked up by a junior admin in an hour a week.